
India's smart home market is growing fast, but voice control hasn't caught up. Most users rely on Alexa or Google Home - platforms that require setup, speak primarily in English, and have no native understanding of the Havells device ecosystem. For the many households that have already invested in Havells appliances, controlling them by voice means jumping between apps, linking accounts, and learning a new command syntax that doesn't match how they naturally speak.
Voice is emerging as a primary interaction layer, 90% of new users prefer regional language interactions, demanding more natural, accessible interface
The brief for Voice Mode was to build an AI powered voice agent that feels native to the Havells One app, works with zero configuration, and speaks the way Indian households actually speak. No jumping between apps. No Alexa. No Google Home. No account linking. Just talk.

Before touching a single frame, we spent 2 weeks auditing how existing voice assistants behave in a smart home context. We looked at Alexa +, Google Home, LG, and a handful of regional players like Atomberg to understand where the experience falls apart for Indian users.
The Multitasking Parent walks in with a sleeping toddler, hands full - navigating an app isn't an option.
The Elderly User is frustrated by small text and complex menus, and needs the system to respond in Hindi when he speaks in Hindi.
The Allergy Sufferer says "ghar ki hawa saaf kar do" and expects the right device to activate at the right setting - without naming the device or the room they are in.
Voice Mode introduces an agentic AI assistant within the Havells One app that allows users to interact with their smart home using natural, conversational language.
It Thinks (Understands intent, language & context) ➡️ Plans (Uses AI capability to decide the best actions across devices.) ➡️ Executes (Meets user’s expectation with logic intelligence)
Instead of manually controlling devices or creating automations, users can simply express what they want to achieve. The system interprets user intent, understands contextual cues, and orchestrates multiple devices seamlessly to deliver the desired outcome.


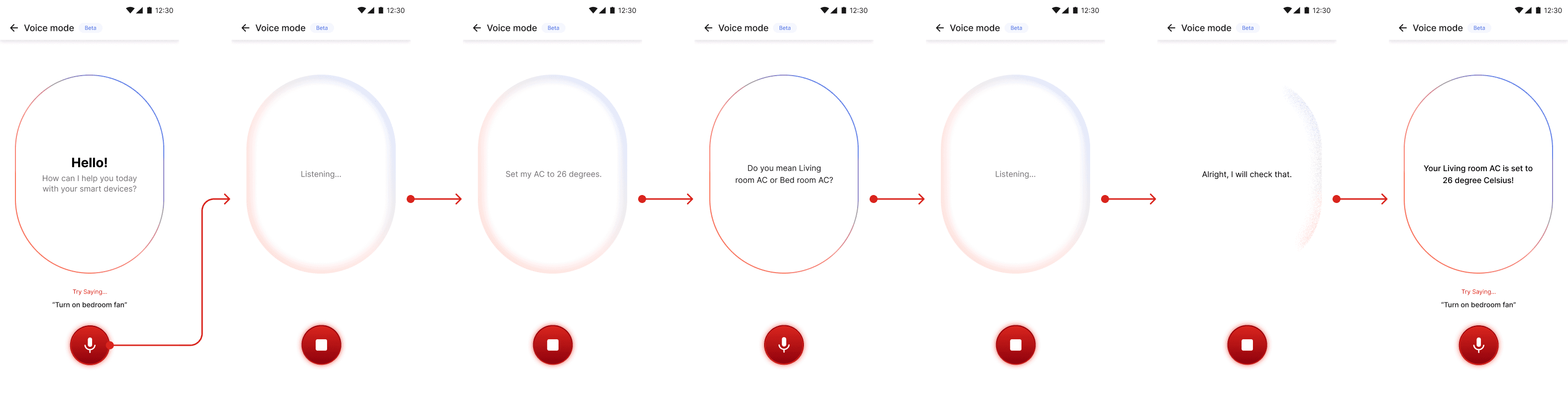



Static screens are easy to design. What Voice Mode actually needed was a system of motion that communicated three distinct states - idle, active, processing - through changes in the oval's feel without ever being distracting. The principle we kept returning to was "motion with intent." Every transition had to serve a communicative purpose: state change, feedback, or emotional tone.


